以後關於 Web 開發技術的東西,我會同步或 優先貼在 Rocodev 的 官方 Blog 裡面。
裡面除了我的技術文章之外,也會有我們優秀同事所寫的一些技術文章,如 Sublime Text 2 Packages for Rails
歡迎訂閱! http://feeds.feedburner.com/rocodev
P.S. Rocodev Blog 裡的文章不一定會 100% 與這裡的 Blog 文章 100% sync。
如 SCSS 開發原則:禁用 @import 'compass'; 這篇我就沒有打算貼過來,所以建議各位兩邊都訂…

Rails4 在前天的 RailsConf 2013 釋出 Rails 4.0 RC1 了,這也表示大家應該可以進場了。
上個月在 Rails 4.0 beta1 時為了練手感,把手上的一個中小 production 專案,也上了 rails4 branch。
大概有幾個感想:
Upgrading to Rails4 這本書強烈建議要買,才 $15 USD,可以節省你不少 debug 時間。
升 Rails4 建議不只開 branch,也用 rvm 開一個 gemset 出來作,因為 gem dependency 變更蠻多的。
rails4_upgrade 要裝。這個 gem 蠻好用的..可以幫你掃 dependency 問題。事實上 Rails3 升 Rails4 最討厭的是 gem dependency tree,因為 Rails 3 已經出太久了(幾乎快兩年了吧),很多 Gemfile 都強綁定 3 ,所以升 Gemfile 時會出現很多問題...
major gem,如 simple_form, devise, 幾乎都有 beta1 版,裝了就保證可以動。小的 gem 也幾乎都有 rails4 branch 可以 hotfix。(起碼我在 beta1 進場時遇到的問題就幾乎都有解,所以在 rc1 的狀況應該會更好)
這次 Rails4 的改動,我個人的感想會是 Rails3 的 New Feature, Better syntax Version。如果平常 code 都寫的蠻漂亮(接口和封裝乾淨)的話,升級應該是沒有太痛才對。唯一讓人很煩的就是 gem dependency 解不完,還有牽扯到 scope 與 query 的部份幾乎都要重寫..:/ (目前是都還跳 warning 而已,但真要清 warning,如果 model 裡面 condition 很多,真的會清到手快斷...)
有關於 New Feature 與 Better syntax 這個議題,我應該週末會寫一篇出來..
Rails project 的本體內容物是沒有改動太大,但大家拿來 build gem 的 internal API 改不少,這也難怪 Jose Valim 這一兩天也同步釋出了 Crafting Rails Applications (2nd edition): Expert Practices for Everyday Rails Development 第二版的 beta。我這幾天改 gem 要升 Rails4 也是中了一堆 api 變更的地雷…
會逼大家都改 gem 的原因是因為是,連 migration api 都改了,所以只要提供產生 migration 的 gem 通通會逼要升 Rails4,真是個好招 -_- (連我只有兩個 commit 的 AutoFacebook gem 也不能倖免。解法在這裡 )
Obie Fernandez 前天也宣布了 Rails 聖經 The Rails 4 Way開始 beta。值得注意的是他這次是使用 Leanpub 釋出書籍的 beta,而非走 Informit 的 RoughCut 版本。
為什麼我有時間測這些東西?好問題,我也不知道…明明最近就忙到快死了...orz
我寫的兩隻 gem bootstrap-helper 與 boostrappers 目前都釋出 Rails4 版本了。
- gem install bootstrap_helper -v 4.2.2.1
- gem install bootstrappers -v 4.0.rc1
有任何問題,請回報到 Github 上的 issues 上。
Boostrappers 是針對我在 2013/03 月底測試 Rails 4.0.beta1 測出來的 solution 更換掉 gemset 的。目前應該是沒什麼大問題...
不過這次值得注意的是,Rails4 底層又換了不少 API,包括 generator 的 action 和 migration,所以為了 bnootstrappers 的升級,我被迫 release 了三隻 gem。
包括我之前寫的 AutoFacebook,也被迫出了一個 Rails4 版本。
- gem install auto-facebook -v 0.1.rails4
最近公司頻道從 IRC 換到 Hipchat 上面,本來也想要把 Hubot 也一起搬過去的。
但是 Hubot 的安裝真是惡夢,光是 node.js 版本和 npm 之間的 dependencies 就可以搞死人。我們公司現在又沒有專職的 SA,工具蠻多都是我自己下海寫的....
最後想了一下,決定找一套在 ruby 下也很好開發的 hipchat bot framework。
最後找到這套 isis。因為敝公司 是 100% 靠 Ruby 吃飯的,所以瞬間就把寫 bot 的門檻拉到很低...
掛上 hipchat bot 的方式
因為 bot 是常駐在聊天室的,所以你必須要幫 bot 申請一個 hipchat 專用帳號。
hipchat:
jid: DDDD_XXXXX@chat.hipchat.com
name: Full Name
password: <password>
history: 3 # num of history fields to request
rooms:
- DDDD_room_name@conf.hipchat.com
# - DDDD_second_room_name@conf.hipchat.comBot 走 Jabber 通訊協定。Jid 和 Romm 的資訊在 https://yourcompany.hipchat.com/account/xmpp
jid 格式 DDDD_XXXXX@chat.hipchat.com,room 格式 DDDD_room_name@conf.hipchat.com
開發 / 掛上 Plugin 方式
isis 的 plugin 撰寫很簡單。基本上只要到 lib/isis/plugins 多開一個 class 繼承 Isis::Plugin::Base,然後掛進 config.yml。
這樣就做好了...
Local 測試
bin/isis run 就可以把 bot 跑起來了。而若要背景常駐要跑 bin/isis start
Deployment
開發完畢推上 git 之後,要讓 bot 重開還要跑到 server 上跑 bin/isis restart。懶人如我當然覺得這很麻煩,所以我用 gitploy 和 Rake 檔寫了 autodeploy,跑 rake deploy 就會動了。
順便還參考 hipchat/hipchat-rb 的 deploy 檔,做了 deploy hook 掛在 bot 的 deploy rake 上,這樣起碼有人 deploy bot 時大家會知道,以免 bot 被搞爛了沒人發現...。
config/gitploy.rb https://gist.github.com/xdite/5424771
Rakefile https://gist.github.com/xdite/5424780
後記
昨天後續還寫了幾隻常用 bot,比如說「午餐吃什麼 bot」、「redmine #issue_number bot」、「網頁自動抓標題 bot」。
不過這不是重點,重點是 bot framework 架好之後,禮拜五晚上同事們竟然不睡覺,一直在惡搞這隻 bot 瘋狂加功能....XD
看起來 bot 的確可以玩出不少花樣啊...
這是一兩個禮拜前貼在 Facebook 牆上的心得。整理一下重貼在 Blog 上...
整理一下過去幾年的心得,如下:
JD 部分
寫清楚 Job Description
- 寫清楚公司能提供什麼(薪資福利)
- 希望對方已經有什麼經驗?(已具備什麼技術,什麼職位就寫什麼)。
不要徵超人
不要徵 「超人」。徵「超人」沒有意義。
這裡的超人若以 Web 界來比喻,就是你可能看到 JD 這樣寫「熟 Rails、熟 jQuery、熟 ORM、熟 API 設計、熟 OO Design、熟....」
若一個工作職缺,出現「超人」的內容。通常表示:
- 這個公司只缺一個人,就是做到死的超人。Developer 不是笨蛋,看了也知道雇主想幹嘛…
- 雇主不知道自己想徵什麼人。這對 Developer 來說也是危險訊號。
如果你不是這種心態,是認真想招到合適的人。那麼請把需求寫清楚。
- 如果團隊用 Git 很深,那麼寫上「會使用 Git」。
- 如果團隊用 Rails,那麼寫上「熟 Rails」。
- 如果團隊用 Rails,願意收 junior,那麼寫上「具備 MVC 開發經驗」。
不要貪心寫得希望對方什麼條件都具備,這樣十之八九只會收到一堆充滿 BuzzWord (對方希望合你胃口嘛)的垃圾履歷,大大拖慢你篩寫出正確合適的候選人的速度。
必須要理解到一個現實,不是每個人一進公司,就有辦法馬上 pickup,寫一堆「熟OO」並沒有任何幫助。只要寫應徵此職位的「最低條件」即可。
舉例來說:因為如果對方不會 Git 你又不想 train 他 Git,你就要寫「會使用 Git」。如果你可以接受 train 對方 Git,只要寫「不害怕 Command Line」即可。不然寫一個「熟 Git」,雙方都不知道這到底是「熟」是要「熟」到什麼程度…
不要請對方直接寫信到 jobs@mycompany.com
通常這樣做的下場是,「你會覺得自己會收到一堆來亂的履歷」。這不是應徵者的錯,因為你沒告訴人家「你想看什麼樣的履歷」。
而且,不是人人都有辦法寫出「有重點」的履歷。
我建議的方式是乾脆設計一張表單,請對方照格式填。不需太制式,但你可以用這種方式引導對方把他自身的重點 highlight 出來。而且 fit 你的需求。
這樣可以節省你在看履歷時很多時間。
Appsumo 的 Noah Kagan 在 Learn Chief Sumo's Proven Automated Hiring Formula 也是用了類似的手段。只不過他做得接近自動化…
至於我們公司的 應徵表單,我是這樣設計的..
把招聘啟示貼在正確的地方
徵人公告只是一篇文章,你可以貼在任何地方。
但就我的經驗是,貼在你平常在混的社群裡就好,不要到處亂貼。高曝光率對招聘一點幫助都沒有。
怎麼說呢?這幾年下來,我發現共事過最棒的同事,或收過來看起來不錯的履歷。都是在社群裡面徵來的。不是在社群裡面原本就有見過面的,就是看我的 Blog 在徵才,寫信過來應徵的。再不然就是平常有在 Facebook follow 動態的人。
至於那些在其他地方看到徵才啟示寫過來的履歷。怎麼說呢?你真的會覺得他寫過來的東西「不合胃口」。
相信我,收到「很多」履歷,絕對也不是什麼好事...。因為最痛苦的往往不是你已經很忙了,卻招不到人。而是你已經很忙了,還要花上一堆時間過濾履歷;挑來面試的人,還瘋狂浪費你寶貴的時間…
Noah Kagan 在 Learn Chief Sumo's Proven Automated Hiring Formula 這篇其中的一個招聘技巧。也是建議不要到處亂貼,儘量把徵才啟示、通知放自己家產品的 Facebook Page 邊欄,或者是產品網站、產品通知信裡。
這些原本就認同你產品的人,有極大的機會 fit 公司 culture。而不是網路上的任意陌生人。
其他
這篇文章已經太長了。下次有空再來寫 interview…
一直以來( 5-6 年前開始..),我都是用 IRC 在管團隊的 Log 和通知。
這個習慣最早以來是跟前輩學習來的。這在比較強悍的技術團隊內部,幾乎是行之有年的標準 Convention。
( 可見 Flickr 著名的 10+ Deploys Per Day: Dev and Ops Cooperation at Flickr
投影片 (P.52),不過他們大概 2006 年就開始這樣做了,這篇只是後來比較漂亮的整理...)。
當年 在 T 客邦,也是用 redmine + IRC bot 自己搞了一套。
把 Log 都打到 IRC 有很多好處。團隊成員去開會、或者暫時離開。回到電腦前,還是可以很快速的掌握剛剛發生了什麼事。再加上 issue tracking 或者是 system alert 其實是很洗信箱讓人容易分神的東西,所以我們把這些幾乎都搬到 IRC 上,建立出一個可以非同步但又高效率的合作開發模式。


不過這個模式還是有一些極限,所以最近在 survey 過後,最近我決定把 公司 整套 solution 搬到 Hipchat 上。
主要搬家原因
- 發現每個同事一進來都要教怎麼用 irssi + 工作站掛 irc,學習成本很高
- 公司聊天室是 skype, log 在 irc 上,開兩窗有點麻煩。加上 skype-bot 不是不能作,只是我覺得 skype-bot 很吵…
- 人員離職很麻煩,因為要把 irc room 的 key 和 info 整套換掉,無法作權限控管
- demo 給別人看 irc solution 時也很麻煩,因為對方一定看得到我們的 key ....
- 對 irc 訊息上色要試很久,對一般的 developer 門檻有點高
- irc log 多半要切到桌機才能看,沒有 mobile solution。
所以最後就整套就搬到 Hipchat 了。看起來大家現在是用的蠻習慣的。

Hipchat 的好處
- 主要是 Web Based,但有 iOS, Android, Mac, Windows, Linux client
- 有 group 和 permission control,踢人加人很方便
- API 整合,寫 bot 很容易
- 聊天行為與一般 IRC chat 蠻相近的
- 貼圖貼檔案貼 Link 很方便
- 一樣會存歷史紀錄,就算離線了,重新上線還是可以找 Log
- 很多主流系統整合支援( github, redmine, capistrano, airbrake….)
- 5 人以下現在是免費的方案…
Hipchat integration
我們目前是把目前的幾種 Log 都打到 hipchat 上
- Github (github 的 hook 支援 hipchat, pull request, push , merge 都會通知...)
- Capistrano Deploy http://blog.hipchat.com/tag/capistrano/
- Airbrake ( server error 通知系統, airbrake 支援 hipchat )
- Redmine (官方的 hipchat/redmine_hipchat 不好用,所以我自己改了一隻 rocodev/redmine_hipchat 出來)
之後還會掛更多東西上去…
Here are the reading marterials I recommend in 2013:
Basic
If you are new to Ruby / Rails world, I suggest you take following courses :
- Code School Try Ruby
- Code School Try Git
- Code School Git Real
- Peepcode Meet Command Line
- Peepcode Advanced Command Line
- Zed Shaw Learn Ruby The Hard Way
Learning Rails
Use following courses to build a simple application, like a "forum"
- Code School Rails for Zombies Redux
- Code School Rails for Zombies 2
Basic web development
- CodeSchool jQuery Air: First Flight
- CodeSchool jQuery Air: Captain's Log
- CodeSchool CSS Cross-Country
- Codecademy Javascripts
Intermediate Ruby on Rails
( If you are not familer with TDD with Ruby on Rails, these two books might be a good start)
- Michael Hartl Rails Turtorial
- Ryan Bigg Rails in Action 4
UT on Rails is also a excellent learning material
- Schneems UT on Rails
Testing
- Code School Rails testing for zombies
- Code School Testing with Rspec
- Noel Rappin Rails Test Prescriptions: Keeping Your Application Healthy
- Thougutbot Learn Test-Driven Development using RSpec and Capybara.
Advanced web development
- Code School Jounry into Mobile
- Code School The Anatomy of Backbone
- Code School CoffeeScript
- Code School Assembling Sass
- Code School Assembling Sass Part2
Refactoring Ruby / Rails code
- Codschool Rails Best Practices
- Chad Pytel / Tammer Saleh : Rails Antipattern
- John Athayde / Bruce Williamsp The Rails View: Create a Beautiful and Maintainable User Experience
- Eric Davis Refacotoring Redmine
- Code Climate 7 Patterns to Refactor Fat ActiveRecord Models
Writing better Ruby code
- Code School Code Ruby Bits
- Code School Code Ruby Bits Part 2
- David A. Black The Well-Grounded Rubyist
- Russ Olsen Eloquent Ruby
- Avdi Grimm Confident Ruby
- Avdi Grimm Exceptional Ruby
- Stefan Kaes Writing Efficient Ruby Code (Digital Short Cut)
Podcast / Journal of writing better Ruby/Rails code
Object-oriend Design in Ruby on Rails
- thoughtbot Ruby Science
- Avdi Grimm Object on Rails
- Russ Olsen Design Patterns in Ruby
- Jay fields Refacoting : Ruby Edition
- Sandi Metz Practical Object-Oriented Design in Ruby: An Agile Primer
Know Rails better
- José Valim Crafting Rails Applications: Expert Practices for Everyday Rails Development
- Marc-André Cournoyer Owning Rails: The Rails Online Master Class
- Railscast Rails Initialization Walkthrough
- Railscast Rails Middleware Walkthrough
- Railscast Rack App from Scratch
- Railscast Rails Modularity
- Railscast Hacking with Arel
- Railscast Authorization from Scratch Part 1
- Railscast Authorization from Scratch Part 2
- Railscast Action Controller Walkthrough
- Railscast Action View Walkthrough
Guideline of writng Ruby / Rails code
- ruby-style-guide
- rails-style-guide
- rails_standards
- thoughtbot guides
Resources of latest Ruby
Github 今天上了新的 features: Contributions 。
在新的個人頁面可以看到過去一年自己 Commit 的軌跡...。
看了一下,我公開的 commit 有 923 次。
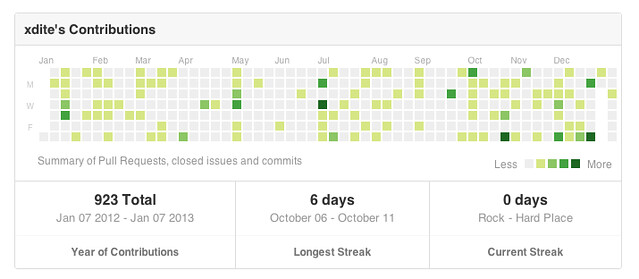
含 Private repo (公司和自己的 side project),有 3363 次。
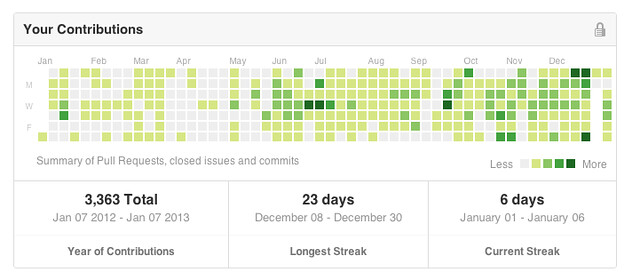
另外一些之前整理在 FB 上的數據。2012 年,我:
- 出國了四次
- 去過了三個國家
- 給了超過 10 場 talk
- 完成了五個案子
- opensource 了兩個熱門 gem
- 拿了一個世界大獎
- 開了一間公司
- 開發了超過 10 個 Rails porject
- 寫了超過 60 篇文章
- 寫作了超過 30 萬字
- 讀了超過 200 本書......
加上去年一整年 commit 的 3300 次。
到底哪來的這麼多時間啊?..orz
結論是,應該要來放個假了嗎?
Essential Rails Design Patterns
http://rails-101.logdown.com/books/3-essential-rails-pattern
限時特價 9.99USD
被大家嫌拖稿很久的本書,終於在 12/22 新增了接近 8 萬字,共 165 頁的內容。
Rails 101
http://rails-101.logdown.com/books/1-rails-101
限時特價 4.99 USD
( 籌備 Rails 4.0 版本中 ,到時候會寄出免費更新 )
特價到 2012/12/31 午夜為止。
開始有計畫整理一些在 RubyConf China 大家線下問我的問題的答案。
挑選出來暫定的第一篇是大會期間詢問度最高的:「如何閱讀 Rails 原始碼」。
想要「閱讀 Rails 原始碼」的原因很多,不過多半的出發點都是想要能夠設計出更好的 Plugin (Gem)、或者是希望能在程式碼出錯時,能夠更快在 Rails 原始碼快速找到答案。
但擺在眼前的事實是, Rails 的原始碼已經成長大到成幾萬行的怪獸,如何「看懂」或者是有效率的找到答案,已經變成是一個很大的難題。
以下是我根據這幾年的經驗,能夠給各位的建議:
1. 從單純的部分切入,例如 Helper
最令大家頭疼的地方是,這麼多程式碼,要從哪部分開始讀起。
如果你是初心者,想要跳進這個池子裡,想找點簡單的東西讀,我會建議你先從「Helper」的部分開始讀。「Helper」是整個 Rails 程式碼裡面最獨立的部分(不牽扯到 request 呼叫),而且結構相對單純。
2. 從 request 開始,到 rack,到 routing,到 controller,最後再到 model
我真正開始有系統的讀懂 Rails code,是從一門線上 Owning Rails開始的。這門課的宗旨是,就是教你有效掌握搞懂 Rails 的核心與結構。相當有趣的是,他並不是教你讀任何 Rails 代碼,而是實際一步步帶你造出一個「mini Rails」。而造完這個 「mini Rails」之後,學員也能夠開始神奇的開始擁有快速找 code 的能力。
我在去年曾經寫過一篇 Owning Rails masterclass 介紹過這個課程。
第一天:造出自己的 mini Rails
帶你如何寫出精簡版 ActiveRecord、寫 rack app、用 rack app 改出精簡版 ActionController、自己 implement 出 before_, after_, around_ filter、自己 implement 出 view。然後最後再用你自己刻出來的這套 mini Rails 寫 web application。
第二天的課程
Refactor 昨天寫的 mini Rails,教你如何 trace Rails core。利用 Rails internal API 客製化出你想要的特殊 function、library。作業有 custom validator、custom finder、create responder、create form builder、使用 Railtie 客制 Engine、造 plugin。
宥於這是付費課程的關係,我也無法公開提供各位更進一步的教材內容。但是我能夠告訴各位這們課程為什麼會這樣設計,讓你可以也依循著這個軌道去自我進修。
rack
一個 request 進來,首先通過的是層層的 rack middleware。所以必須要先理解什麼是 rack,rack 的運作原理是什麼。可以試著自己先寫一個 rack app 玩看看。
如果想知道 Rails 裡面的 request 流程會經過哪些 middleware,被加過哪些工。可以在 Rails 專案裡面打 rake middleware,再去把 class 一個一個叫出來讀。
routing
request 通過 rack 層進來後,首先面對的是 dispatch 問題,Rails 透過 routes.rb 進行 dispatch。而如何 dispatch 到正確的 controller,中間靠的就是 regexp。
controller
開發者在 controller 會牽涉到兩個常用的相關機制:Filter 與 View Rendering。Filter 時怎麼運作的。method 應該是回傳「值」,怎麼做到自動回傳的是 render 出來的view。
model
ActiveRecord 的上一層就是一套 ActiveModel API。其實 Rails 不一定要靠 ActiveRecord,也可以透過實作一個 Class 加上部分機制做出自己的 ORM。其中 validation, finder 都是這方面的課題。
3. 搞懂 Rails 的啟動流程
RailsCast China 曾經 release 過一個很好的影片:The Rails Initialization Process By kenshin54
講解了整個 Rails 啟動流程。你也可以讀由 Ruby on Rails 官方釋出的這篇官方教學啟動流程去更加了解啟動過程中究竟會經過哪些檔案,如果要寫 plugin 可以 hook 在哪一些部分。
4. 實際簡單寫一個 Rails Plugin
最好的學習方法就是動手實作。在看過以上這一些資料之後,我建議你可以實際透過開發一個 Gem 去更加了解整個 Rails 內部的結構。
目前 Rails Plugin 幾乎都是以 Engine Gem 的形式釋出。所以透過撰寫一個 Gem,可以了解到:
- 如何將自己的 Library 與現有 API 整合
- 如何將自己的 Library 掛 / 不掛進啟動 process 中。
- Engine 與 Railtie 的結構
- 如果有相依檔案,如何撰寫 generator,把檔案放進去 project 裡面。
- 如果有檔案操作和客製選項,如何透過 thor 這個工具去達到檔案修改的目的。
算是一個相當好的鍛鍊。
5. 讀別人(熱門)的 Rails Plugin
有時候,想要實作某一些功能不得其法。最好的方式就是去讀有類似功能的 Gem,去看看其他作者怎麼做的。有時候會翻到他們用了不少你根本不知道的 Rails API。
順著他們用這些 Rails API 的方法,可以更快的在 Rails 原始碼找到你要的答案…
小結
希望以上的方法能夠協助各位更快的上手讀通 Rails 的原始碼。有任何問題歡迎留言在底下討論。