這是我今年參加 RubyConf China 2012 所給的演講。
不過這個投影片裡面的不少內容,是在現場直接解說掉的,所以只看投影片的話,可能不會知道這樣的設計慢在哪裡。這陣子比較忙,如果有空的話,過一陣子我再寫一個全文版的。
這個演講的主旨是:在以往,我們設計 Rails Application 時,為了想要寫出一些漂亮的架構,會參考一些 Best Practices,或者是參照官方 Rails 官方指南的 Convention 建議,進行設計。
但是這一些 Convention 或依照直覺的軟體設計,很大的成分其實會造成你的 Application Performance 下降。這些問題即使你裝了 New Relic 還是絕對抓不出來。而這些設計可能也不太能算是 Rails 或者是相關套件的錯,甚至是 nobody's fault。這個 talk 會帶你找出這些問題,解釋原因,並且給出修正方案。
昨天看到神人 vgod 寫了一篇 過早最佳化是萬惡的根源,這篇文章是不錯。但是,對於「職業」那邊實在有太多奇怪的假設。
想了一下,決定還是在 FB 寫了一下我的看法,然後再轉貼到這裡來。
===
簡單回一下好了。關於職業的部分。我本來也是覺得就如同跟 @vgod 一樣所說,在裡面可以全新鍛鍊和學習各種知識和技能。
我在大學裡面,就是抱著這樣的心態,學習各種知識。我在大學裡面最認真修的課,不是數學(唯一感興趣的是線性代數、離散數學、代數)
,而是....去修資科系基礎理論的課,什麼作業系統、計算機結構、演算法、資料結構、數位電路、etc...大概能修的我都修了。數學系最
重視的微積分、高等微積分,我沒有很喜歡。而且,我大概下課的時間都泡在系上的機房,弄網路、伺服器、寫寫簡單的網站。
而最後我也是抱著這樣的心態,選擇了第一份工作。因為我覺得大學的環境才能讓「自己有選擇想練什麼武功的自由」。
我希望一直這樣持續下去。
然而,接下來的事情。你們知道了,我被打臉了。狠狠的打了一巴掌。
那一天,我才發現我關在學校自己練的等級,跟職業的人是差上那麼多。這才是讓我選擇馬上離開那個環境的主因。
很多人以為「自己有選擇想練什麼武功的自由」,才能讓自己的 power 開到最大。我對這件事情有截然不同的感受。為什麼職業的環境會成長很快。因為上班領錢,才有限時被交出成果的壓力。而且那個壓力能造成的動力是遠比自己下定決心要練什麼技能的動力還要可怕的。上班,你會被迫限時學到跟這個領域所有「基礎」的工具。一個月「基礎的程度」,可能直接贏掉自己自由學「半年」以上的程度。
而且特別是,如果你的同事和老闆,都是佼佼者的話....。到現在我還是相當感謝曾經共事過的 @gugod, @ihower, @gslin, @hlb, @嬸嬸 XD
我學到的就是。如果你想把什麼東西學好,稍微深呼吸一下(當然就是自學一點皮毛,希望不要進去之後死太慘),就跳下去...。
害怕溺水的恐懼會被讓你瞬間就學會游泳。(如果你跳下去就死拜託不要怪我...orz)
如果你曾經看過我半年前寫過的為什麼我想創業 一文。
你就會知道,我在這四年裡面「被迫」學會了多少事。
職業工程師,並不是只有用 PHP 寫了一千個論壇和購物程式那麼無聊。老實說,寫到第二個第三個,你就會知道 Framework 的重要性。
當然,如果你之後玩到神兵級 Framework 如「Ruby on Rails」。那麼你還會更會知道,這世界不是只有 CRUD。(Ruby on Rails 本身
的架構採用了大量 Patterns of Enterprise Application Architecture 這本書裡面的實作,裡面也大量用了 Design Pattern 的技巧)。
不只如此,你還會從周遭的 ecosystem 的 plugin 中學到各種各式各樣的 pratical、theoretical 的佼佼實作。
當這些東西看多了以後你就更進一步的發現,語言根本不是重點,掌握這些「企業級理論」(註)的核心精隨,才是重點。
而當進一步又將 Ruby on Rails 玩的十分純熟之後。就會馬上意識到,用什麼語言寫,把 code 寫得多快已經完全不是重點了。
- 如果專案控管能力不佳,需求一直在改變,那麼就算你的「架構理論」玩的再漂亮都是一樣的,結不了案就是結不了案。
- 如果團隊協調能力不佳,那麼不管公司投再多人進來,累死的就是那幾個人而已。
- 如果時間成本能力不佳,不是會造成公司大虧損賠本,甚至會專案進行到一半就被迫終止。
很多人以為我網站寫的很快,是因為 Framework 的關係。真的不是這麼簡單...,那是我身上擁有所有的技巧綜合出來的結果。
如果我沒有領錢「被迫」進行我很多「不喜歡」的事,我不會學到這一些東西。如果我沒有「被迫」去處在那一些環境,我能學到的東西就限於「我在學校時一開始能望過去的眼界」,而不是環繞在我周遭各個神人的眼界。
而這也是為什麼我會寫出那兩篇文章的初衷。我不是出來走這麼一遭,不會發現我當初那樣的假設,完全不堪一擊。
而再舉一個例子,曾經很多人一直對我,開口閉口就是 Ruby on Rails 值得學習,感到很不解。事實上,我也是從這個 Framework 的進化裡面,
才學到人不能把眼界只侷限在某一個端點。我個人的能力,很大的原因是跟隨這個 Framework 一起成長的。如果我當初不是碰這個 Framework 起來,我恐怕真的沒有這個能力成長的這麼迅速。因為台灣沒有太多「大型」Scale (PV 千萬以上) 的網站,可以逼迫一個工程師直接從最基礎的 Turtorial 中,自學到那麼多 optimze techniques、best practices(更何況這種等級公司的入場卷,也不是你說想要應徵就能應徵上)。
從這個 Framework ecosystem 裡面產生出來的 plugin 也是世界上各式各地的程式設計師貢獻出來的,這裡面融合了他們公司現在「最好」的 pratices,有些甚至是 future architecture。如果我在一間悶頭自幹工具的公司上班,我是沒有機會見識到這一切的。
我不認為自己一開始有多好的眼界,能有辦法看到多棒的未來,並且照著我所看到的事堅定的往前走。甚至,直到現在,我現在還是不認為自己還是具備這個能力。但我唯一知道的是,我不能把自己鎖在自己的眼界裡。
我想說的話,就只有這樣而已。
[註] :Deisgn Pattern、Agile、Testing、Scaling、Performace Tuning …
在上一篇中,我談到了三個能力是我建議培養的:「大量快速閱讀、外語交流、邏輯歸納推導」。接下來我想談談,我會勸你「什麼樣的決定不要作」。
這一篇我曾經思考了很久,我到底要不要認真的寫出來。(考量到文章刊登出來的批評聲浪)
最不值得做的事
1. 漫無目的的拿高等教育學位(大學、碩士)
台灣已經來到一個瘋狂的病態狀況。大學錄取率超過 100%。什麼人都能夠上大學。甚至大學招不滿人,還拜託對岸的大陸學生來念大學。
來念大學的人,往往也不知道自己來念大學的目的是什麼,只是因為爸媽叫自己來念,就來這裡放空四年等畢業。因為負擔不起學費,於是半工半讀,甚至多數學生整個大學生涯都在打工,唸書反倒是兼差而已。
在寫完上一篇文章的時候,有讀者發問:『私心希望加上「後悔以前沒有做什麼」的部分 XD 』
我必須要很認真的說,我最後悔的是:『後悔沒有拒絕我爸的願望:去念大學』。
別誤會,我並不是要說後悔曾經念過這間學校、後悔去念應用數學系。(甚至我這一輩子最感謝的就是當年被大學老師鞭策出來的極佳邏輯能力)
而是,早知道我喜歡的「作網站」這個職業。並不需要靠付高額的高等教育學費就能取得相關知識,並變成職業從業者。我不需要逃避那些我不喜歡修的課,修我根本沒興趣的學分,只為了取得學歷在等畢業。
因為甚至我翹課的時間,都是在宿舍玩架站或者是泡系上機房弄伺服器…
我可以早一點去就業,早一點為社會有貢獻。而不需要國家浪費在我身上的寶貴高等教育資源。最輝煌的四年時間被當年不懂事的我,浪費在「滿足我爸對我的表面期望」。
我爸真正的期望應該是希望我成為一個有用的人,不會餓死自己,對社會多少有貢獻。而不是去「拿一個大學學位」(取得一個大學學位是他『希望』的一種『表現形式』)。
這黃金的四年我浪費了很多時間在閉門造車,在揮霍人生,而不是真的認真的幹一些有意義的事業出來。
** 我的能量一直等到大學畢業後、終於不用躲躲藏藏的滿足別人對我的表面期望之後,才用力的迸發出來。如果可以,我希望我一開始就不用花時間在這件事情上。**
而一直到出社會、甚至當主管以後,我才開始意識到全民盲目的拿高等學位這件事,對國家的競爭力是多麼可怕的傷害。很多人以為讀大學用的都是自己的錢,浪費學費也是自己家的事。事實上,完全不是這回事。不管是讀公立大學或者是私立大學,國家都花了非常多錢在你身上。每一個人讀大學的成本,其實並不是光光只有學費而已。事實上政府對每一間學校的大量補助,才讓你可以每學期以最多只繳五六萬的代價就取得學位。事實上若真要計算,一個學期正常的每人教育成本應該是幾十萬台幣...。
但是,這當中有多少比例的人真的渴望上大學唸書?恐怕真的很少。幾乎絕大多數的學生都把念大學當作是可以打電動郊遊的坐牢而已。國家投注四年心血,結果學生放空放四年。
這完全是巨大的實體資源(金錢)以及黃金的無形資源(年輕人的青春)浪費。但卻沒有人對這件事情提出質疑。
大家都覺得外國人都超厲害,十幾歲二十幾歲技術就都超強,做出超屌的網站,創上超級厲害的公司。為什麼台灣人沒辦法?
很簡單,因為台灣人的人生從 22 歲才開始…人家 15-18 歲就開始了...
很多人也害怕,如果沒有一個大學學歷會找不到好的工作,有不錯的薪水。我出社會、當上主管以後才知道企業選才的標準完全不是你念哪個大學畢業的。而是你專業技能的純熟度、你當年的可塑性(年紀)。(換句話說你越老,但技術越嫩,競爭力只會越來越弱。)
沒有一個好的大學、碩士學歷,也只會影響你「第一分工作」的起薪。「第一分工作」並不是人生的全部。「第一分工作」只是唯一一個人家願意容忍你犯超級愚蠢錯誤的地方。
把時間浪費在『坐學校牢』上,完全沒有意義。如果你有一件事超級有熱情,那麼你就應該現在去作。如果你想光宗耀祖,那麼你應該從現在開始。
爸媽不會跟你說這件事,而他們會認為我在傳邪道。
2. 不要去當研發替代役
我的不少朋友和同學都是男生。他們不少人選擇服替代役,而不是直接當兵。我可以跟大家說,他們剛錄取的時候第一年都很開心。然後,然後,然後他們就不會再跟你講後面的故事了.....
因為大家都很後悔。但是你聽不到這些後悔的聲音。
每當有大學生在 conference 或社群聚會攔住我,詢問我對於未來的建議規劃,每次聽到有人想去再念個碩士,念完個碩士想再去當個替代役…
我總會試著勸他打消這個念頭,因為我知道後面會發生什麼事。但是我永遠都擋不住,因為他們總會堵我一句:「替代役 pay 起薪比較高,而且三年有保障...」
我聽到這一句,我就不繼續再講下去了。因為再講下去,我又會看成是「邪道中人」了。
現在看來,經歷了這一段歲月之後,我會回頭認為,也許台灣的「科技替代役」制度,原本是為了保證科技業人才的來源,以及保護科技業人才不因為當兵一年之後退伍變白癡(後來我覺得這有點像是都市傳說,因為不少人上班後被操了一兩個月後,魂就回來了。)。
** 但後來某種程度上,我認為是把台灣優秀人才殺光光的一種可怕制度.... **
為什麼?首先是「研發替代役」的資格需要「碩士畢業」。
嗯。聽到「碩士畢業」,其實多半就是「放空....」。
放空兩年,接下來綁三年的研發替代役的生活。
為什麼綁三年替代役通常是開始後悔的起點?因為真實的狀況是,有辦法申請到研發替代役的公司,多半是已經相對有經濟規模的大型公司了。雖然他們有辦法給上「穩定」的 pay。但是通常役南們能拿到的也就是「穩定的工作內容」,沒有什麼特別性的機率拿到能夠開疆拓土的機會(逼自己成長)。穩定 pay 保證不低,但是幅度通常也跳不高。
其實出社會頭三年,是一個人很黃金的三年。因為第一年有人願意大幅負擔你學習犯錯的機會。接著第二年,你開始不再犯錯了,大致上可以開始摸出自己擅長什麼,適合往哪個方向走。第三年,開始有籌碼換上 pay 更好的工作。(而這個 pay,運氣好的話,甚至可以拿到比剛出社會高上 1.5 甚至 2 倍的數字)
而科技業的工作更現實,每三個月風向就換一次,每六個月技術就革命一次。甚至每年的黃金主題,都不一樣。
許多人會後悔。原因歸納不出以下幾個:
- (1) 現在工作,三個月就不喜歡,但是他不能跑,於是之後 2 年 9 個月的日子,放空…
- (2) 現在工作,做得算有點興趣。但是完全沒有向上向左向又突破的空間,只好放空…
- (3) 外面有更好的機會,有超級好的 pay,跑不了。有被外國挖角的機會,也跑不了。放空…
你可以觀察到,最後的狀況幾乎都是放空…
放空完浪費了多少歲月呢?這樣一輪下來,通常都是 27,28 歲了… 這時候,他們才開始想找自己「真的有興趣的工作」。但,門檻這時候變得非常高...
我身處在這個火熱的軟體圈子,時不時的就會接到很多軟體獵頭信(國內外都有)。不少的 offer 都相當好,只是囿於時空背景,無法接受邀約。最後,他們也總會希望我推薦幾個優秀的人才,因為想進入台灣拓展分部,而他們都願意給的起非常非常好的 pay。
這不是偶爾才發生的特例,我一天到晚都在接到這種的詢問信…
但我卻總是只能愛莫能助。因為能夠介紹的優秀人才不是正在「替代役」,就是正在「念碩士班」準備「替代役」,或者是根本還沒當兵(年紀太小或太老正在閃兵役)。
而對方也沒辦法接受,收進來的工程師 27,28 歲技術還是很菜的 junior ….(因為這個年紀,在外國都應該要是 Senior Engineer 或 Architect 了)
矽谷蓬勃的軟體生態,在於優秀的人能夠在各個公司靈活流動,把各個公司優點有效的交互傳播。同時,因為沒有誰被簽約綁死的問題,所以人才可以不用浪費大量時間在放空等出獄,想換領域鍛鍊就換領域。三年的鍛鍊就變成架構師,根本不是不可能的事。
只要有天份,只要沒被綁死,幾年內都有機會鍛鍊出萬丈光芒。你也許說不是每個人都拿的到外國的好工作。第一年當然不太可能。但是第三年,誰能曉得會發生什麼事呢?
但是我們的社會觀念卻是,把流動視為不成熟。把綁架回來互相浪費看成保障。
你要怪世界進步的太快,我們追不上。怪政府無能,拖累國家競爭力。我卻認為是我們自己活生生憋死了自己。卻還在找替罪羊。
3. 不要自願關在一份你根本不喜歡做的工作,下班再找機會作喜歡的事
要是我能從出社會的幾年來,得到的最寶貴教訓,無非是這一課了。
** 千萬不要白天去作完全不喜歡而且沒熱情的工作(即使薪水看起來還不錯),晚上再用閒暇時間找機會作自己有熱情的事。**
也許你聽過了很多,熱血車庫創業,下班努力扭轉人生的故事。想要努力自己說服自己你也可以…
我不想直接潑你冷水笑你這根本是在做夢。
直接來說說自己的故事好了。
我出社會之後頭兩年,也有這種美麗單純的幻想。當時也是選了一個我沒有太討厭沒有太喜歡,但上班時間規規矩矩做事。晚上可以有很多時間「偷玩」自己喜歡的東西(寫部落格、寫網站)的工作,而且最重要的,這個工作還是一份鐵飯碗...(半公家機關,符合我家對我的期望)。
直到兩年的某一天,碰上一個技術遠高於我卻大我沒幾歲的前輩。才意識到原來當初這種這種想法簡直是自 high,是在自毀長城。
人家每天上班八小時都在玩自己喜歡的東西。我每天下班還要努力擠才有兩小時可以進行業餘可笑的練習。不要說綻放光芒了,光是要追上他,我要努力到什麼牛年馬月 -_-?
那個禮拜過後我馬上就辭職了。
我還沒有時間馬上想清楚我未來要幹什麼。但我很清楚的知道一件事:再這樣繼續下去,很快我就會被我自己挖的洞埋掉。
一兩個禮拜以後我跑去找了一份我應該有興趣的工作開始幹,就是職業的網站工程師,
四年過去了…
四年過後我站在這裡。這一路上經歷過的事簡直遠超乎我的想像。我蓋出來的網站、我的部落格文章讀者不計其數。我經歷了很多各種好笑、感動的 event(你可以 google 到一大堆)。我透過網路,結交到了一大堆沒見過太多面,卻很交心的朋友。我在我這個年紀,玩到了超過正常人應該玩過的網站專案數量。在奇怪的年紀當上資深經理。在完全沒心理準備的情況下拿到世界賽首獎。
對一件事情有熱情真的是一件很可怕的事情。
我在這個奇妙的旅程中發現一件鐵律:有熱情的事情你才有動力把它做得好。而做得好,就很容易
生出成就感。而這個成就感又會激起你更大的熱情,把事情做得更加好。而一旦你把某件事情做得無人能敵,奇妙的機會就會自然從天上掉下來。
從前不知道怎麼敲門得到的機會。會在幾年後的某一天,以意想不到的方式掉在你面前。而因為身上的技術已經不再是僥倖。所以就算這個幸運可能是意外,也能夠牢牢的被抓在自己手中,不再溜走。
有些人總覺得我總是能得到的奇妙的幸運,或者是到底哪來的這麼無窮詭異的毅力在充實自己。我只能告訴你這是熱情。我喜歡作這件事不只是每天的 8 小時。我每天花的時間是 12 小時。甚至是週末還把這件事情當娛樂。
所謂「一萬小時的威力」並不只是個噱頭而已。他是真的會產生 something 的,而且這個 something 無窮巨大。
要是我當年選擇了繼續作這一份沒有溫度的工作。什麼事情都不會發生。因為我一輩子可能都只會是一個業餘工程師。只能繼續躲在角落酸別人,他是幸運他是幸運…
我不知道為什麼在台灣的大家都有一種奇怪的執念。要是經濟有虞就算了,無虞也要逼自己作自己不喜歡做的事情。再說服自己其實下班可以再擠時間偷做,然後這樣總有一天就有機會出頭。
我學到的唯一一件事,就是喜歡的事情就絕對不要當業餘。一個月的職業訓練,就足足幹掉三年的業餘偷練。而把一件事情做到真正好,上天會讓接下來的一切順理成章出現…
如果你只是為錢作一件你完全不喜歡做的事,相信我,你真的會每天活得就好像在地獄裡。而給你再多 pay 當補償還是一樣,因為下班為了發洩情緒,你還是會選擇把它狠狠花光。但相反地,要是你正在做的事情是喜歡的事,其實收多少 pay 你可能根本也不在意。而且,當你喜歡到能夠把這件事情做得非常好。那麼那個數字上天是不可能少給你的。
小結
這兩天寫了這麼多字下來。我發現我自己也遠遠寫超過了未畢業的大學生可能看得懂的範疇。但無論如何,我還是想把這些悶在心裡很久的話寫出來。
即便冒著被人罵邪道的危險。我試圖告訴大家,其實
- (1) 可以不需要念大學
- (2) 替代役可能不是幫你解套,而是有可能斷了你無限未來的一條路
- (3) 熱情比什麼都重要
最起碼我想拿我自己來說,應該可以看起來應該是一個很難被挑骨頭的例子吧。我是一個普通家庭出來的普通小孩,大學念的也是大家看起來很普通的系(甚至可以被人說不好的學校)。而一直到 24 歲之前,我都按照著普通家庭對我的普通期望,過上一個非常普通的人生。
唯一的不同,就是我在 24 歲以後開始想清楚了,我不應該再為了滿足別人的表面期待去過我的人生,眼前可以走的路,也不是只有政府和爸媽所說的那幾條路而已。然後我就這麼出發了。
而我在這個旅途中,也看到現在世界是長什麼樣的。這也是為什麼我寫了 三個要學習的技能、三件不要去做的事。
(1)世界正在以越來越快的速度再演化。快到現在任何的國民教育完全跟不上的階段。從前必須要上高等教育才能修到的學分,現在都可以透過網路越來越容易的取得這些知識,甚至超越本國大學可以供應的範圍。而從正規大學取得的知識,從前在畢業後還可以保值個兩三年。現在可能還沒出校門口就直接過期了。
是不是要花上這個四年取得越來越被廉價化的學歷,坐上四年根本沒有人喜歡的大學牢,背上你潛意識裡面覺得根本不應該背的大學學貸。我覺得這是可以思考的事情。
(2) 我們爸媽的時代,跟我們身處的時代,其競爭以及變化的程度,完全不可同日而語。這十年間科技的變化程度大家也看到了。而這個速度只有可能更快,而不會更慢。所以是否真的有那個價值繼續依照爸媽陳舊的建議悶著頭走一條「放空的路」?
很多人總是說,台灣的人才素質很高,但卻很奇怪的沒有辦法在世界上綻放光芒。某種程度上,我認為就是因為我們長期以來雖然「聞」到世界正在劇烈的變化,卻還是悶著頭走著一條老早過期的路,但還是期望著會有一個比別的國家更好的結果。
我們社會繼續用著奇怪的迷思,把未來有希望的孩子,一一推進黑洞裡。(不用說推,很多人甚至根本是搶著自己跳進去。)幾年後發現不對了。才在電視政論上抱怨以及檢討為什麼高等教育廉價化,為什麼花了四年書只有 22k。為什麼我們的國民素質高,但是長期競爭力低落?
(3) 但隨著世界交流的門檻逐漸降低。取得國外的工作機會真的沒有那麼難。而且就以我身處的網路業來說,隨著全世界的軟體缺工潮,英文還可以的 Senior Developer 簡直人人都搶著要。
(我所在的這個圈子,美國矽谷挖美國其他州的人,美國挖加拿大的人,加拿大挖日本的人,日本人挖中國的人和台灣的人。大家到處互相挖來挖去。因為缺工...)
這世界機會簡直是太多了。完全不是只有「澳洲屠夫」才能真正賺得到錢。每當只要電視上報導,念完大學畢業,結果只能到別的國家「打工度假」賺錢當台勞(明明是國家培養的高級知識人才,卻選擇跑去用勞力賺錢)。我內心就真的只有「國家的教育資源又泡湯了」的感想…
學弟妹在我演講結束後,曾跑來問我,到底我們這個科系的學什麼技能才有求職競爭力。我給了他們一個他們沒有意料過的連結:Github Job board。而不是 104 …
多逛逛這裡,你就會知道練什麼技能是值得投資,而且也是大家需要的。
** 看世界,不要只看台灣。**
我想我這兩篇文章,要說的可能從頭到尾就只有這九個字......
前天,應母校 文化大學應用數學系 的邀請,再次回系演講關於大學後的職涯規劃。這已經是第二次受邀演講相同的主題。受邀的原因相當單純。純粹是我的表現一再的讓系上老師跌破眼鏡,在短短數年間一路從不起眼的小職員,迅速累積出社會普世價值觀上相對可觀的成就。( T客邦技術部經理、HTC 資深經理、Facebook World Hack Grand Prize…etc.) 所以老師們想邀請我回校演講。分享我在這一路上成長的感想,並給予學弟妹人生建議,回答對於對於將來路上的一些疑惑。
會後的問題,我一路上其實在各大場合都答過類似的問題。內心對於大學生缺乏適當明燈指引,相當感慨。有些問題我想甚至可能只有我這樣的經歷的人,才可能答的出來。這些建議我覺得若只限於在校學弟妹才能聽到,相當可惜。所以趁記憶猶新,把它整理出來。
當然,這只是基於我的人生經歷,做出來的建議。並非絕對,還請讀者自行判斷斟酌。
最值得投資的技能
1. 中文速讀
我最常被問到的問題其中有一個是:「你覺得出社會前你練過最值得的技能是什麼?」對於這個問題,我的答案毫不猶豫的會是「中文速讀」。
為什麼是「中文速讀」?坦白說,在小時候會選擇投資這個技能,原因純粹是 (1) 被逼 (2) 我有天份 (3) 可以在短時間看完一堆雜文小說很爽。
18 歲前,「速讀」這個技能對我來說,是可有可無的雞肋。但是在 18 歲以後,遇上網際網路的高速成長,整個世界呈現一個「資訊爆炸」的狀態。原先的雞肋技能,搖身一變成為我一路上闖蕩的最厲害武器。
原本我個人學習的速度,還被大大牽制在老家附近的書店販售書種的數量。因為網際網路的爆炸性成長,我的閱讀視野一下子被拉到網際網路的邊界。而高速的閱讀速度,即便在資訊爆炸的今天,我還是能夠只花上極少時間,就能夠輕鬆追完今日關注 timeline 上的大小事…
工作上遇到任何疑難雜症,也能透過閱讀速度以及網際網路,快速的整理出相對應的解決方案。
如果時間只能投資在一個專業技能上,我毫不猶豫會推薦你選擇「中文速讀」。
2. 英文能力
其次,我推薦練習的技能就是「英文能力」。每當學弟妹聽到我這樣說,無不哀號遍野,瞬間卻步。
其實,學弟妹不知道的是:所謂的「英文能力」真的非常非常重要。重要到超乎你想像。我出社會到現在的感想是,「英文能力」的重要性也遠超乎我當年的想像。
不只是所謂好的工作需要英文(外商工作需要聽說讀寫)。甚至是幫助你高速成長,超車過同儕的專業知識也通通都是英文 (如同我現在賴以為生的專業技能: Ruby on Rails )。就別說這麼專業的進階知識好了。
就連外國的許多線上初階自助學習課程:CodeSchool、Codecademy。也都是英文教材。
其實台灣不乏素質高的軟體人才、學生。其實只要正確的導引,具備適當的教材與練習,成果往往能突破目前國民教育造成的限制。唯一可惜的是,大家往往只要聽到「是英文的」,下意識就刪掉這個選項。我一直覺得這是一件可惜的事。
很多學弟妹也許會期待,將來這些東西有天會有好心人出中文版。就我的觀察,這個機會可能是越來越小。目前的現實是:這個世界呈現高速成長中,能夠翻譯這些知識的人,往往也是能夠少數能夠突破天際線以及國際限制的人。他們目前的聚焦,無不是專注在自身能力與事業的突破。很少能夠還有資源和時間能夠停下來拉別人…
於是造成了一個極端的現象:強者越強,弱者越弱。甚至就算強者有心停下來救別人,有時候往往也不知道怎救起...
大家對於「英文學習」的盲點,在於英文學習很枯燥,無法靜下心來投資一個「不知道有什麼報酬率」的知識。
其實各位可能不知道的是:在大學之前,我的英文能力也非常非常的弱,每次段考都只有 30 分。但是我現在的英文能力,卻能讀聽能說能寫(哈,抱歉,有時候 blog 還是一堆 typo 錯字)。跟外國人順暢的聊天和工作的能力我應該還算是不錯的。
如今我具備的所有專業知識與能力,甚至是得到的機運,也全部都是因為英文賺進來的。
現在回頭看,英文練得起來的原因,只是因為我的一個單純的小嗜好:「看美劇」。其實把英文練好並沒有那麼難。我雖然不喜歡「嚴肅的學英文」,但卻非常喜歡看美劇(含字幕)。劇情精彩是我當初被深深吸引的一個原因,十年來我看過不下千集美劇。
習慣美國人講話的速度,是我進步的第一環。習慣了聽美國人講話,自然腔調與口語速度就會自然而然接近美國人。聽說能力就自然起來了。
因為不害怕英文,在需要大量接觸英文的程式開發專業環境下,就會完全不覺得英文是什麼可怕的門檻。很快的,自己就會習慣「太平洋其實並沒有加蓋」這件事。
能夠接觸到的機會,看到的世界,就不會被所謂的「台灣洗腦電視台」蓋台進入無窮迴圈。(其實我已經接近十年沒有在看台灣新聞與連續劇了…)
我認知到的一件現實是,現在全球已經進入非常扁平化而且快速變革的激烈變化中。如果國家國力本身夠強,還抵的住這種變化的衝擊。但是台灣,在經過這四年政府無作為且大量惡搞的狀況下,本地機會迅速的惡劣、變小、變少。
如果不能夠把自己變成全球需要的人才,將很快的被這波洪流吞噬。如果你的英文能力不好,勢必只能是被吞沒的那一群人…
3. 寫作能力與程式開發能力
其三,我認為值得投資的部分是:「寫作能力」或者是「程式開發能力」。
每當我一提到這兩件事,也是很多人馬上會皺起眉頭。
但我一路上走來的感想是:我很高興能夠同時都把這兩塊能力練得不錯。而且是這兩個能力,才把我帶到今天這條路上。
(也許你認為我能夠拿到 Grand Prize of Facebook World Hack,是個程式奇才,其實我可以很清楚的跟你說:我明白自己不是寫程式的料。
我真正有狂熱興趣的是寫作以及作產品。我小學立志當作家或歷史學家。成為一個厲害的 Developer 從來不在我念大學之前的志願選項。
我只是喜歡作網站,我被迫去學 coding,去學有關 coding 的 everything,然後莫名其妙的就被迫站在這個領域的前端…
)
寫作能力與程式開發能力,帶給我的影響是:
寫作能極大化的強迫把我沒有章法的思緒收斂在一起,當累積到能夠把想法準確的寫下來,並重複的寫到讓人家明白。最大的受益人其實是我自己,我透過寫作梳理以及掌握了整件事的來龍去脈。能夠把事情精準的重複,才是弄懂整件事。透過不斷的寫作可以大大強化「把事情想清楚」這方面的能力。
程式開發也是類似的事。Knuth 曾經說過 「A person does not really understand something until after teaching it to a computer」。電腦並沒有很聰明,它只能執行絕對有邏輯的事情。換句話說:你在教電腦事情的時候,其實是在釐清自己的思考與整件事的邏輯。沒有邏輯的事,你又如何期待可以被 work 呢?
而培養寫作能力與程式開發能力,其實最大的好處不是培養出強大的邏輯核心能力群。而是產生出來的副產品:「文章」以及「程式碼」。
很多 Developer 常常怨歎,我也很有能力,為什麼沒有人要挖掘我?很簡單的道理,因為沒有人知道你作過什麼。沒有文章放在 Blog 上,沒有程式碼放在 Github 上,沒有可以實際端出的 project。光憑短短的幾分鐘面談,和洋洋灑灑履歷。誰能在這麼短的時間,知道你是不世出的曠世奇才呢?
如果你想要世界看到你,你必須要做的就是,主動站出來。
小結
現在的社會絕對不是爸媽從小告訴你的那樣:只要專注「上學唸書」,找份「穩定的工作」就能安穩一輩子的社會。相反地,這個社會正用以往沒有的速度,每半年每三個月就快速演化一次。
以具體的例子來說,就看看你身邊的電腦、平板、手機演化趨勢就知道了。2007 年之前有誰能預期到 Facebook 能夠演化成如此怪獸?
世界上的工作型態以及職務需求,也在這幾年間劇烈的變化。昨天在蔡依橙醫生的部落格上面看到這一段話:『至於台北,他們根本不想拿來比較。我們還在講古老的「四小龍」攀關係,人家已經在亞洲制霸的路上了。』
在台灣媒體的鎖國洗腦下,其實很多人不知道,台灣已完全從先進國家之林掉出去了。很多人以為選出馬英九,即使無能不做事,其實也不可能把國家害到多慘的境界。這真是大錯特錯,在 2007 年以前,台灣與世界的差距真的還沒有那麼大。2008 以後的這黃金四年,全世界都在往前衝,以每三個月一變的速度在進化,只有台灣還在原地沾沾自喜的原地踏步。四年過去了,我們國家以及人民的競爭力完全不知道掉到哪裡去。
我不是跑得很前面的人,我真的只是勉強跟著世界的速度一起跑而已。
很多學弟妹常直接希望我給他們一些將來就業方向上的建議,該選什麼學科好,該選什麼職業好。老實說,在這麼瞬息萬變的社會改變裡,我實在無法告訴大家,什麼職業絕對賺,絕對不會被淘汰。因為這種事已經很難繼續再被持續發生了。
但無論如何,至少我可以告訴大家,如何不被世界變化的速度甩開....我認為這三項核心能力是至關重要的。無論社會再怎麼變,至少你還可以靠這三個核心技能維持個人的競爭優勢。
- 中文速讀
- 英文能力
- 寫作 / 程式能力
這一篇是關於「什麼技能建議學」。下一篇的主題我將談「什麼樣的決定不要作」。
paperclip.io 是我與 zhusee 最近奪得 Facebook World Hack 大賞 的作品。T 客邦在 Facebook 公布大賞得獎名單後 (10/15) 第一時間採訪了我們。
獲得 T 客邦 授權,將 12 道採訪內容轉貼回來我的部落格。
1、為什麼會選擇開發 Paperclip.io 這樣的服務?你們發現了什麼樣的需求?這個點子是怎麼來的?
我平常在使用 Facebook 時,到不錯的連結或頁面就會順手按讚。但是,按完讚之後過後想找自己前幾天曾按過什麼連結,卻很麻煩。Facebook 一直沒有一個入口介面可以讓你找之前讚過什麼。我認為這件事造成我相當大的困擾,就覺得應該要有一個開發者來寫一個這樣的 App 幫助大家....但很明顯應該是沒有人要寫,於是我就打算自己寫。
剛好 Facebook 舉辦這次比賽,我就打算拿來當這次的題目。
2 、在 Facebook Developer World HACK 2012 裡面,因為每個站都是一天的活動,而且比賽時間只有幾個小時,在這麼短的時間內,你們做了什麼準備,讓作品可以贏得比賽?
選題
首先,我認為是「選題」吧。這是一個「夠小」而且「解決真正大眾困擾」的題目。如果我們選擇進行這個題目。可能題目賣相就會高一點。(我猜)
專注
其次,我認為是「專注」。因為這個「題目」夠小,我們可以把我們的火力集中在於完成核心的實作。主要核心就只是兩隻 API 爬蟲 和網頁爬蟲。這兩個部分很快就寫完了,我們剩下的精力都在調整介面的順暢度。
賣相
第三,調整 demo 時的賣相。因為上台前需要寫投影片和 live demo 自己的作品,demo 只有短短的 5 分鐘,我必須在這麼短的時間內讓評審和其他的參賽者,一目了然知道我們的服務在做什麼,解決了什麼問題。於是我註冊了一個假帳號負責 demo,這裡面的內容是我精選過的,可以看完之後就了解我們在做什麼(我本人 like 過的資料其實很雜亂)。 讓評審能夠一下子理解我們想要作什麼,解決了什麼問題。我想也是拉高勝率的一大原因。
炫技
第四,介面炫技。zhusee 是一個很強的前端工程師,我經常提了一堆的點子,他馬上就能用很炫的方式實作出來。我們嘗試在 demo 前能夠讓所有的介面非常的流暢(即便是等待時間)。另外也花時間做了高難度的首頁特效,吸引目光焦點(畢竟是 Hackathon….當然要炫耀一下)。
3、在整個活動過程中,讓你們印象最深刻的事情是什麼?
參賽的台灣隊伍都很強很有創意。我不知道原來大家會拿 Facebook API 惡搞出這麼多的創意。比如說 Memory Millionaire,我就覺得他們的點子相當有意思。
在宣布三大獎項之後,我們其實一度很失望…一度以為自己落選了。
直到評審宣布評審特別獎,我們發現得獎名單也沒有我們(這也落選會讓我受到很大打擊XD),我們才猜測可能是我們拿到了首獎!!
4、開發 Paperclip.io 總共用了多少時間?在這個過程中,有沒有遇到什麼樣的難關?
其實在比賽之前,我有試寫了一個很小的 prototype,練習 FB API 的存取,但是,成品很糟,存在很多問題。但是因為已經熟了 FB API,我大概覺得這個網站主體架構,在比賽的時限之內,我是有把握可以做完的。
原始設計存在不少問題,用改的拿去比賽太麻煩了。我決定到現場重寫一遍。我們從上午九點到會場,就一直馬不停蹄的在寫 code,寫到開始 demo,所以我也不清楚我們整整寫了多久。
不過中間的確有遇到幾個重大難關:
首先是網頁的爬蟲演算法優先順序問題,當初在設計時,設計的 worker 演算法不好,會造成前面使用者資料沒抓完,後面使用者資料就無法開始進行。這在使用者體驗上會非常不好,因為使用者會覺得網站壞掉了。於是我們花了幾乎整整一個小時打掉原先的 worker 重新設計。
再來是搜尋索引效率的問題,我們嘗試讓這些連結是可用關鍵字被搜尋的,但是資料是分批分批抓進來的,所以會有異步索引的問題。我一直都無法好好的解決這個問題,最後心一橫,不解決了。直接用 MySQL 全文檢索…
不然我們可能會被迫在上台前拿掉這個 feature(但我認為搜尋是一個很大的賣點)。
5、Paperclip.io 隊伍的成員有兩位,你們之間如何分工?
我(xdite)主寫整個網站的架構,設計爬蟲、梳理流程、製作投影片以及上台簡報。zhusee 實作強大的視覺特效以及繪製精美的 UI。我會先把需要加工的頁面在第一時間寫出來,交給 zhusee 操刀設計,我們用 git 控制程式碼,基本上可以做到全速各寫各的,毫不干擾。
6、在 Paperclip.io 的功能裡,有個 Recipes 的分類,讓人很好奇為什麼會特別把食譜做個分類出來?又,書本、食譜這兩個分類的內容,是怎麼去判斷的呢?
在把整個網站初稿寫出來之後,我們認為這個網站如果只有連結實在太單薄了....
於是我們決定加一些分類。分類就是按照 og:type 去分,我們發現有幾個 type 做出來的視覺效果不錯,如:Youtube、食譜、Github …於是我們就決定把這些功能加進去了。
7、在得獎之後,是不是打算升級 Paperclip.io 網站的硬體資源,讓匯入的資料可以更快跑出來?
這個網站吃的資源真的很驚人,我不確定我能不能一直養著它…
說到這個,其實在現場邀請一些朋友幫忙測試時,我們就發現一些效能上的問題了。於是,我們還在當場做了一個非常大的賭注,就是現場刷卡升級 linode 機器(伺服器)。這時候已經快要接近 demo 時間了,要是升級當場出了什麼問題,或者機器來不及當場升級完畢,我們可能就直接開天窗了… 還好這件事並沒有發生。
8、對於想要參加類似 Hack 活動的人,有什麼樣的建議?
我參加過好幾次 Hackathon,得過兩次獎。一次是 2008 年的 Yahoo Open Hack Day(那次是公司同事一起出去比賽,作品是「和多繽紛樂」,得了亞軍)。一次就是 2012 年的這次 Facebook World Hack 得到首獎。
在這好幾次的參賽經驗中,我得到幾個寶貴經驗:
(1) 好的題目很重要
評審希望得獎的題目是 valuable 的。搞笑、諷刺、主題模糊的題目,一定不會得獎。(我在 2009 的比賽跟一群大神等級的朋友合作做了一個精美的搞笑網站「我是專家」,但是…我們沒有得獎)
(2) 賣相非常重要
有些 Hackathon 比賽,甚至投影片比網站重要…。有某幾次的 Hackathon 比賽,竟然是投影片贏了網站。這讓我覺得很不公平也很無奈。但我也理解到比賽要贏就需要賣相的現實。 雖然這次 Hackathon 大會是要求需要提供 source code 以證明不是投影片的實戰比賽,舞弊不至於發生。但我還是認真的投資了快要一個小時在調整假 demo 帳號、截圖、寫投影片.....
9、接下來還會參加其他 Hack 活動的計畫嗎?
暫時沒有。因為我們忘記報名今年的 Yahoo Hack Day 比賽。但我想沒有關係,今年拿到這個獎就值得了…
10、如何把 Bootstrap 改得這麼好看?
我們用了一些網路上的免費素材,比如說
簡單抽換了一下材質,然後用了一點 CSS3 技巧,提升介面質感。這些都是我們平常開發時就相當熟練的技巧,用得很自然。
11、從零到完成作品,用了很短的時間,這是怎麼做到的?有什麼樣的密技?工作進度如何管理?是有什麼樣的開發好習慣嗎?
我想主要是幾個重點:
(1) 時間管理
我參加過很多場 Hackathon。大概知道寫 code 時最容易踢到什麼鐵板。或者開發中最容易遇到什麼鬼打牆的事情。
比賽通常只有短短的幾個小時,所以你要把最浪費時間的部分想辦法節省掉。比如說:如果當天再討論 idea,你的時間就很有可能不夠用。網站需要佈署,佈署需要測試,所以最好有只要一鍵就能 deploy 的環境。domain name 全球生效需要時間,所以 domain name 最好先買。
現場再搞這些事,網站鐵定作不完。何況最後至少要留半小時寫投影片....
(2) 知道什麼該放棄
因為時間不夠,所以其實很多功能,不夠時間讓我們寫到夠完美夠好。於是對自己在開發任何元件時,都要設定 deadline。如果一定時間內(15 min' 30 min)寫不完,就要放棄,或者是改採其他 solution。
(3) 平常要有自己的 best practices
作網站的時候,我們知道很多工夫都是重複的。比如說作網站一定要有一個網頁主框架、一個 Facebook 登入系統、一個系統管理介面,一些常見的分享功能。
這些事情都小,但是堆起來還是很花時間。如果比賽時,這部分的時間成本若是 0,我們可以把更多的時間花在寫核心功能上。像我上禮拜釋出的一個 app 產生器 Bootstrappers。
這個 Bootstrappers 其實就是我這次比賽時用的大砲,它可以讓你一鍵就產生一個網站雛形,然後馬上開始刻程式。所以當別人還在討論要作什麼時,我這部分已經作完了....
而我和夥伴已經一起工作將近三個月,彼此有不錯的默契。我們在寫 code 時,了解彼此寫 code 的習慣,於是接力對方的部分,速度就非常快。而我們更用了 git 這套程式碼版本控制系統,可以做到各寫各的,不會干擾。
12、如果 Facebook 邀請你們加入當員工,會進去嗎?
會慎重考慮。
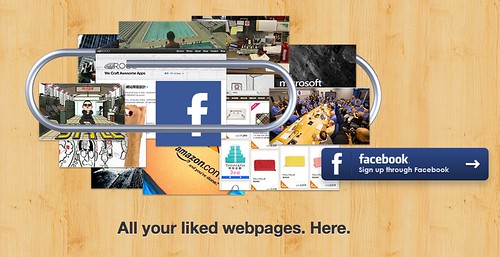

Hi, everyone. I am happy to announce the new service I recently built at 2012 Facebook World Hack Taipei : 「Paperclip.io」. Not only won the “Best Overall” prize in Taipei. We also win the Grand Prize of World Hack .
News here: World HACK Recap and Winners
====
We're pleased to announce the Grand Prize winners, whose projects stood out from the many high quality apps. These teams have won a trip to Facebook headquarters in Menlo Park, where they will meet with members of the Facebook engineering team:
The Paperclip.io team, from Taipei. Paperclip.io indexes and sorts the things you've liked on Facebook and across the web, so you can easily browse your likes by category or by the date you liked them.
The Chained Story team, from Buenos Aires. Chained Story is a web version of a storytelling game in which players take turns adding a sentence or paragraph to a story. The completed story can be published to a user's timeline.
The BoostMate team, from Moscow. BoostMate analyzes your social graph and the connections you have with all your friends, producing a ranking of who you're closest to, who you interact with least, and whether those interactions were positive.
====
各位好,前陣子在 Facbook World Hack 奪下台北站首獎的作品paperclip.io。我們很高興的宣布,這個服務再次奪下了 Grand Prize of World Hack 。獎品是前往 Facebook 總部一遊。
我們很高興能為台灣爭了一口氣!謝謝大家一路上的鼓勵!
新聞連結在此:World HACK Recap and Winners

這是我本週剛釋出的一個 Gem: Bootstrappers。是一個 Rails 專案產生器,特色是內建馬上套好的 Bootstrap theme 和 其他好東西。
Bootstrappers 的開發緣由
身為一個職業開發者,我開啟一個新專案的機會實在太高了。但是,你知道的。每次要開發一個專案,無非就是 rails new project_name。然後打開 Gemfile,添加一些常用 Gem,再修改 application.html.erb,塞塞設定,填填 CSS,修修 HTML。
Bootstrap 以及其他 rubygems 是很方便,但是把他們組起來還是非常花時間。次數多了,我就覺得這樣的初始化動作實在很煩。
於是,我第一次的嘗試,就是作一個空專案,把我平常的 best practices 和 templates 都丟進去。如果有開新專案的需求,再 copy 過去。
但是,隨著時間更迭,我又發現更煩的事了。就是我還是得花上一堆時間改 namespace 與 setting。而且,裡面內建的 rubygems 會過期,等於還要花時間 ugprade 這些 template。而最煩的還是:Rails 本身自己也會過期!而要升級的小版本,自己可能還要補一堆 config,而這些變動真的很難追蹤。
於是,最後我下定決心要來研究 App Generator 到底要怎麼寫。我實在受夠了每次的 c/p + modify 了。
(之後我也許會寫一篇如何製作 App 產生器的文章 )
最後 Bootstrappers 就這樣誕生了。
內建好康
這個專案裡面目前內建了以下這些 Gem 以及相關 Template :
- Bootstrap SCSS
- Bootstrap Helper
- SimpleForm
- WillPaginate
- Compass
- SeoHelper
- Capistrano
- Cape
- Magic encoding
- Settingslogic
- Airbrake
- NewRelic RPM
- Turbo Sprockets for Rails 3.2.x Speeds up your Rails 3 rake assets:precompile by only recompiling changed assets
Powerful Features
特點如下
- 現成套好的 Bootstrap Theme (application.html.erb)
- 搭配的 Bootstrap Helper,快速兜出表單、選單、按鈕、Dropmenu、ajax modal、alert、breadcrumb 等等…
- 套好的 WillPaginate (with bootstrap style)
- 套好的 SimpleForm (with bootstrap style)
- 內建 Devise 會員系統
- Bootstrap useful hacks (比如
body { padding-top:60px }、dropmenu 自動展開等等) - Boostrap override best-practices
- MagicEncoding : Ruby 1.9 自動添加 utf-8 宣告
- 自動掛上 Compass
- SeoHelper : 自動幫你的網站產生 page description / page keywords
- Open Graph : 自動幫你的網站產生 og description / og_image
- Facebook JS、Google Analytics
- Capistrano / Cape
- Asset Pipeline 加速器
- ….etc.
一些我平常開發專案時,累積出來的 best practices。
有了這個武器,你現在可以使用 bootstrappers project_name 這個指令,一鍵瞬間就產生出一個不錯的 app,而不用擔心套版問題以及一些基本的網站優化問題。
歡迎 現在就試看看 !
Bug / Pull Request
https://github.com/xdite/bootstrappers/issues
歡迎各位回報錯誤,或者提交 Pull Request。當然,如果能夠直接提交 Pull Request,是最感謝的。
我還會繼續把一些還沒丟進去的 best practices 繼續整合進去。如果各位有興趣幫忙的話,歡迎查看 TODO.md。
在我的前一篇文章「Specification by Example - 團隊如何交付正確的軟體」,我提到了一件在工程師界,人人皆知卻不願意說出口的「秘密」:
「工程師竟然時常比他們的雇主或PM,更了解它的生意邏輯與流程」。
「客戶在它的 Spec 裡面卻指定了完全不可行或者是成本效益極低的作法」。因為簽了合約或領了老闆的薪水,我們被迫在明知不可而為之的狀況下,進行了一個徹底失敗的專案。」
如果你不是身處於工程師這個圈子的話,若無意中聽到這一件事,通常會覺得這群人相當傲慢。這群人不負責執行 Bussiness Development,怎都可大膽有此感想?
一開始,我也對這個「觀察」是存疑的。因為一開始時擁有這個觀察時,我還算是個很菜的工程師,這個觀察對我來說應該是錯覺。但隨著生涯中經歷過許多專案的角色。在專案中,我屢屢嘗試著尋找能夠反駁這個觀察的蛛絲馬跡。但最終都以失敗告終。
而後來更輾轉得知,這幾乎是這個圈子內「不能說出口的秘密」。我才同意這也是真的結論。只是我還是找不出 理論 / 反證。
直到最近,我才從幾段討論中,赫然領悟這件事情也許可能是有一套理論可以解釋的。
一段是從 @yllan (台灣知名 Cocoa 開發者,Nally 作者)在的 Facebook 的 post
====
Steve Jobs 說他很喜歡一個比喻。他以前在 Scientific American 上看到一篇文章,研究各種動物運動的效率,最強的是兀鷹(同樣的運動使用最少能量),人類排名普普通通,可能排在所有動物的三分之一左右。
有趣的是,那篇文章也研究了「騎著腳踏車」的人類,而騎腳踏車的人其能源效率把所有動物遠遠甩在後頭。人類製造工具大幅拓展自己的能力。而 SJ 把「電腦」比喻成「心靈的腳踏車」。
他又認為每個人都應該學程式,因為你在教電腦事情的時候,其實是在釐清自己的思考。這正和 Knuth 的名言「A person does not really understand something until after teaching it to a computer」不謀而合。
====
一段是我在跟與朋友的網路爭辯中,脫口而出寫出來的一段話(我常常從辯論驗證中,突然找到靈感,這些感想甚至是我自己也不知道為何會脫口而出的絕妙結論):
====
xdite : RD 會知道你的生意
xdite : 能不能成
xdite : 遠比你自己早知道
xdite : 因為他們會直接先面臨
xdite : 邏輯能不能實作
xdite : 我們會推測就是
xdite : 1. 合理
xdite : 2. 成本(要作多久)
xdite : 3. 效益
xdite : 剛好就是一個事業能不能做的基礎
xdite : 只是很多人誤以為
xdite : RD 只會 code .....
xdite : 3. 效益 就是...能不能重複用
xdite : 能不能實作 要作多久 可不可以重複利用
xdite : 都不可以 就會懷疑
xdite : 你是賺三小
====
我終於理解,為什麼 RD 會提早知道這個生意能不能成。這根本的原因就是因為他們便是嘗試教電腦事情的第一線人員。也就是會先面對「釐清」實作上「合不合理」的第一個人。
程式邏輯是非常現實的,若這件事不合理,RD 就會面臨「無法實作」的困境。這是其一。
其二:只有實作的人,才會知道這件事到底要作多久。RD 也許有樂觀病,往往他們告訴你需要實作兩週,但往往真實需要的時間也許是四週。但如果他們告訴你,需要半年這麼久,或者是根本作不出來,沒有完工的可能性。那可能這件事就不可能發生 -- 起碼在他們手上。
同時也應該要注意的是,這直接反應了成本的爆增。有時候,這甚至不是換一批執行團隊可以解決的問題。RD 正在試圖告訴你,執行代價高昂,你最好不要白花錢。因為很現實的,他也不想要白花時間…
其三:所有 RD 都非常討厭寫 event code。所謂 event code 就是只用過一次的 Code(因為某些特殊事件,如廣告、行銷活動,只執行過一次即扔的產品)。這類型的程式碼,往往無法被重新用在下一次的類似事件中,只能重新撰寫重新來過。這對任何重視自己心血結晶的人,重新來過是非常累人非常惱人的事。
而這對生意執行面來說,是非常高昂的沉沒成本。一再發生,甚至是不應被允許的行為。
小結
任何賺錢生意無非都是幾個簡單原則:首先,先觀察到一個合理需求。接著針對這個需求設計出一個可執行的解決方案。重複,證明解決方案可以被重製,可以得到收益。接著壓低執行成本,演化出一個可以獲利的模式。而在這段過程中:
- 合理實作
- 時間成本
- 重複效益
是至關重要的。
世上從來就不存在這麼一個假設:「覺得自己有一個偉大 idea,接著偉大的事情就會發生」
而在整個模式的發生過程,RD 正是日日夜夜都要面對這個挑戰的第一線執行者。
如果他們很坦白的告訴你這個想法很蠢,也許這件事就真的很蠢,你應該停下來聽他們怎麼說…

這個禮拜終於斷斷續續用了空檔時間讀完了一本買了卻一直沒時間坐下來好好研究的書「Specification by Example」
對岸的圖靈系列最近也出了這本書的中文版:「實例化需求」。如果你想要觀看這本書的書評,InfoQ 上有一篇不錯的文章:「《實例化需求》採訪與書評」。
這本書給我一種很奇妙的讀後感,因為書中既沒有程式碼,也不介紹任何工具,甚至實際軟體例子也很少,篇幅最多的甚至是模糊的團隊訪談。
但讀完了以後,卻讓我在軟體開發上流程上有了更大的啟發。
交付錯誤的軟體的原因
我是一名職業的軟體開發者。前前後後寫過的軟體專案也有 50 個, 60 個。目前也以開發軟體為生。在我的職業生涯裡面,其實我有一個從來沒有跟人講過的秘密困擾。這個困擾,我相信許多同業們可能也有。那就是 --- 一個專案開發下來,「我們竟然時常比我們的客戶或 PM,更了解它的生意邏輯與流程」
但這個問題帶來更大的困擾是:「客戶在它的 Spec 裡面卻指定了完全不可行或者是成本效益極低的作法」。因為簽了合約或領了老闆的薪水,我們被迫在明知不可而為之的狀況下,進行了一個徹底失敗的專案。
技術很好,團隊也強大,產品也有市場。但還是失敗,因為 -- 「交付錯誤的軟體」。
軟體工程沒教的課題: 交付正確的軟體
市面上有很多書,教人如何敏捷開發,教人測試驅動開發(TDD)。它們可以帶給開發者的好處是可以利用這些技巧將工程時間大幅縮短,降低軟體內發生 Bug 的頻率。
這些技巧對於進行軟體專案不是沒有作用,因為早點完工(把功能實做出來),專案早點失敗,專案可以及早軸轉到較接近成功的方向。
對於正在營運中的公司,內部專案早點失敗,及早軸轉到較接近成功的方向。往往是可接受的。因為總體目標是儘快交付到貼近正確方向的軟體。
但對於目標是交付一個軟體的專案,「交付錯誤的軟體」卻往往是糾紛的起源。但卻也是一個千古難解的課題。對於業主來說,他付錢是希望得到一個「正確的軟體」。但於對於被委託的開發者也往往有苦難言,因為他們得到的指示是「按照業主精確的功能敘述去實作軟體」,「正確與否」不是他們的最終責任。而是否「正確」通常往往也得等到上線之後,客戶根據用戶實測反應才能得知(雖然開發者往往是開發階段就往往能猜測出是否失敗的那一群人)。但這從來也不在合約的責任之內。
而這本書也就是在探討這個課題:怎麼樣的軟體流程,才能交付正確的軟體。
大家沒想到的答案: BDD
這本書繞了很多遠路去講解什麼是 Specification by example,但這也是作者的用意:刻意不使用專業定義字眼如「敏捷」、「測試驅動開發」去輔助解釋,避免整個梳理的流程被大家腦海裡面的術語印象所綁架。
但總體來說,這個結論毫無疑問就是 Behavior Driven Development (BDD)。不過這個 BDD 卻跟我當初學到的 BDD ( from Cucumber ) 印象很不一樣。這也是為什麼這次會花上幾個小時謄下這篇心得。
裡面有幾段 quote 我很喜歡,實際擊中困擾的核心:摘錄如下:
「實現範圍(Implementation scope)含有對業務問題的解決方案或達成業務目標的手段。很多團隊在開始實現軟件之前(在此之前發生的一切往往被軟件開發團隊所忽略),期望客戶、產品負責人或商業用戶來確定工作的範圍。在商業用戶明確說明他們的需求後,軟建交付團隊就依此時現。這樣本應該會讓客戶滿意。但事實上,這正是構建產品開始出現問題的時候。
如果軟件交付團隊依賴客戶給出用戶故事、用例清單或其他相關信息,那麼他們其實是在讓客戶設計解決方案。但是商業用戶不是軟件設計師。如果我們讓客戶去界定範圍,那麼項目就無法從交付團隊已有的知識受益。這樣開發出來的軟件是客戶所要求的,卻不是他們真正想要的。
成功的團隊不會盲目的接受軟件需求,將其作為未知問題的解決方案,相反,他們會從目標中獲取範圍。他們以客戶的業務目標為起始,然後通過協作界定可以實現目標的範圍。團隊與商業用戶一起工作確定解決方案。商業用戶專注於所需功能希望達到的目的,以及他們期望由此帶來的價值,這樣有助於所有人了解所需的功能。然後團隊提議一個解決方案,這樣比商業用戶自己想出來的方案更實惠、更快,並且更容易交付或維護。」
「與我一起共事過的商業用戶和客戶,大多喜歡把需求描述成解決方案;他們很少會去討論想要達到的目標,或者亟待解決的問題具有什麼特殊性質。我見過太多的團隊有一種危險的誤解,他們認為客戶總是正確的,客戶要求的東西總是一成不變的。這導致很多團隊盲目的接受客戶建議的解決方案,然後竭盡全力去實現。」
「在構建正確軟件產品的過程中,確定範圍扮演著重要的角色。沒有正確的範圍,其餘的工作只是在作無用功。」
「人們告訴你他們自己認為需要什麼,通過問他們『為什麼』,你可以找到背後的目標。許多組織不能明確地指出他們的商業目標。然而,一旦你獲得了目標,就應該再反過來從已確定的目標上獲取範圍,可能你會丟棄掉原先假定出來的範圍」
一個實際的例子:對 VIP 免費送貨 的需求
Specification by example 強調的是對於需求,我們必須設計出一個可以被實現的方案,這個方案可以被單獨測試驗證。並且從這個方案與程式碼中演化出 LiveDocument。
書中舉出了一個實際的例子。(整理摘錄)
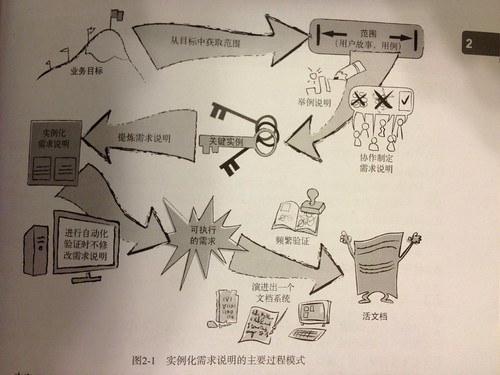
商業目標
12 個月內對現有客戶提高 50% 的重複銷售
實作範圍
我們可以從商業目標中獲取實現範圍。實現團隊和商業投資者一起提出一些想法,然後把他們分成可交付的軟件塊。比方說我們發現一個主題故事是關於客戶忠誠度計畫的。這個故事可以分解成客戶忠誠度管理系統的基本功能和更高級的獎勵計畫。我們決定首先專注在建立一個基本的會員忠誠度管理系統上:客戶註冊一個 VIP 計畫,VIP 客戶有資格獲得特定物品的免費送貨。我們將推遲關於高級獎勵計畫的討論。下面這個例子的用戶故事:
- 為了能對現有客戶作產品直銷,作為營銷經理,我想讓客戶通過加入 VIP 計畫註冊個人信息。
- 為了吸引現有客戶註冊 VIP 計畫,作為營消經理,我要系統為 VIP 客戶提供特定物品的免費送貨。
- 為了節省開支,作為現有客戶,我希望能收到特價優惠的信息。
關鍵實例
一旦團隊開始實現某個特定的功能,我們就可以為特定的範圍產生具體的需求說明。比如,當我們開始作範圍中的第二項 -- 免費送貨時 -- 必須定義好什麼是免費送貨。在協作討論過程中,為了避免運送電子產品或大件物品相關的後勤問題,我們決定系統只提供書籍的免費送貨服務。因為商業目標是提升重複銷售,我們嘗試讓客戶進行多次購買,「免費送貨」變成了「免費為 5 本或以上書籍送貨」。我們要確定好關鍵實例,比如 VIP 客戶購買 5 本圖書、VIP 客戶購買 5 本以下的圖書,或者非 VIP 客戶購買書籍。
接著討論當客戶同時購買了書籍和電子產品時該怎麼辦。有些人建議擴展範圍,例如,將訂單拆分成兩個,只為書籍提供免費送貨。我們決定推遲這個決定,先實現最簡單的。如果訂單中有非書籍的物品,我們就不提供免費送貨。我們加入下面這個新的關鍵實例,之後會再討論。
- VIP 客戶購物車中有 5 本書籍可以獲得免費送貨
- VIP 客戶購物車中有 4 本書及就不提供免費送貨
- 普通客戶購物車中有 5 本書籍沒有免費送貨
- VIP 客戶購物車中有 5 台洗衣機時不提供免費送貨
- VIP 客戶購物車中有 5 本書籍和 1 台洗衣機時不提供免費送貨
帶實例的需求說明
我們從關鍵實例中提煉出需求說明、創建出一目了然的文檔並將其格式化成便於今後作自動化驗證的格式(如下所示)
- 當VIP 客戶購買一定數量的書籍時,提供免費送貨。免費送貨不提供給普通用戶或購買非書籍的 VIP 客戶。
- 假定至少買 5 本書才能獲得免費送貨服務,那麼我們會得到以下預期:
Example:
| 客戶類型 | 購物車中的物品 | 送貨 |
|---|---|---|
| VIP | 5 本書 | 免費、標準 |
| VIP | 4 本書 | 標準 |
| 普通 | 10 本書 | 標準 |
| VIP | 5 台洗衣機 | 標準 |
| VIP | 5 本書、1台洗衣機 | 標準 |
這個需求說明 --- 一目了然的文檔 -- 可以用作實現的目標或自動化測試的驅動,這樣我們就可以客觀地衡量什麼時候算完成了。把它作為 LiveDocument 的一部分,保存在需求說明 Repository 中。FitNesse 的 wiki 系統或者 Cucumber 功能文件的目錄結構就是這樣的例子。
可執行的需求說明
當開發人員開始實現需求說明所描述的功能時,基於需求說明的測試開始時會失敗,因為測試還沒有自動化,功能也還沒有實現。
開發人員會實現相關功能並把它與自動化框架關聯在一起。他們使用自動化框架從需求說明中獲得輸入並驗證預期的輸出,而不需要實際修改需求說明文檔。當驗證實現自動化以後,需求說明就變成可執行的了。
Live Document
所有已實現功能的需求說明需要頻繁地進行驗證,一般通過自動化構建過程來實現。這樣可以確保需求說明保持更新,同時有助於避免功能退化的問題。
當實現了整個用戶故事的時候,需要有人去作首次驗證以確保其已經完成,然後重組需求說明確保它和已實現功能的需求說明是一致的。從需求說明逐步演化出文檔系統。舉例來說,他們可能將免費送貨的需求移到送貨相關的功能體系中,也可能將它們和其他因素促發的免費送貨實例合併在一起。為了更容易訪問文檔,他們可能會在免費送貨的需求說明和其他送貨類型的需求說明之間建立連結。
然後這個循環再次開始。一旦我們需要再次回顧免費送貨的規則 -- 比如,在做高級獎勵計畫,或是擴展功能把帶書籍的訂單和其他貨物訂單分離開的時候 -- 我們就可以使用 Live Document 來理解現有的功能並註明需要修改的地方。我們可以使用已有的實例來協作制定需求說明,同時舉例說明會更加有效。然後我們會舉出另一組關鍵實例,進一步演進免費送貨的需求說明,這部分最終會和需求說明的其他部分合併到一起。這個循環會不斷重複。
為何 BDD 沒有 TDD 那麼流行?
如果你身為 Rails Developer 又看到這套循環格式的話,你會馬上感到這跟一套測試框架很像,沒錯,就是 Cucumber。
我第一次接觸到 BDD 的觀念大概是 2009 年。當然也是因為接觸到 Cucumber,才知道什麼叫做 BDD。但是一直以來,我能夠接受 TDD,但是 BDD 卻一直讓我無法理解。事實上,BDD 也一直沒有普遍流行起來
現在看完這本書,我才理解是什麼的盲點造成了實作上的心理障礙:在一般的專案開發中,通常業主不會要求開發者寫測試(甚至業主不理解什麼叫測試),所以通常測試是開發者自己寫的,為了正確構建功能,以及避免在專案後期踢到大鐵板,所寫的。
但是 BDD 的格式乍看之下卻相當突兀,以 Cucumber 為例,格式是這樣的:
Scenario: Multiple Givens
Given one thing
And another thing
And yet another thing
When I open my eyes
Then I see something
But I don't see something else
敘述一個場景,然後寫下步驟,然後驗證步驟。這對一般開發者來說,BDD 相對多餘以及冗長。
原因何在?這是一般專案中,通常我們只會遇到兩種狀況:
- 客戶疏於描述實作內容 : 只給解決方案,如必須要能夠進行付款。(但是卻沒有講清楚支援信用卡還是 ATM)
所以所謂 BDD 裡面的用戶故事,開發者必須要自行腦內補完。於是只要當「規格」一變,基於規格所生(想像)的整個用戶故事自然就會被摧毀。所以沒有人很喜歡寫這鬼東西。
- 客戶過於精確的描述:對於描述操作步驟過於繁瑣,甚至是規定 UI (比如結帳必須要跳出一個 POP 視窗,等待信用卡驗證時必須要塞入一個等待過場動畫)
這又會變成另外一種情形,開發者把 BDD 當作是 UI 的驗收測試(尤其在使用 Cucumber 中特別容易被誤解)。在網站開發過程中,UI 很有可能是會變來變去的。沒有人會喜歡因為 UI 改變了然後又回去翻修用戶故事....
這就造成了為什麼人們寧願只進行 TDD,甚至只進行 Unit Test。因為比較不可能被需求變動整到。
但只進行 TDD 只能幫助我們:正確地開發一個產品。卻無法達到我們進行軟體開發最終的目標:「開發出一個正確的產品」。
Startup 前期應不應該導入 TDD / BDD?
在去年,我曾經寫過一篇 對 BDD / TDD 的看法,提到 Obie Fernandez 在 Rails Conf 2011 的 lightning talk 曾經給過這樣一個 lighting talk : Why BDD is Poison For Your Early Stage Startup 。並且在演講之後寫了一篇文章 The Dark Side Beckons?
Obie 的觀點正如 talk 名 "Why BDD is Poison For Your Early Stage Startup" 所言。他並且強調了:「Early on in the startup process, it's much more important to be testing against business metrics than anything having to do with code.」
「Until you are able to prove that you have a viable market, that customers will give you money for your product, you shouldn't be sinking a lot of time and money into implementation.」
現在回頭看起來,當時的討論完全是掉入方法論面的論述。我們以為 TDD / BDD 是「正確地開發一個產品」的一個手段。但這個手段會有相對高額的 technical cost。所以在 Startup 早期階段,開發者實際不應該投入過多心力在此之上。因為 Startup 的第一優先是「開發出一個正確的產品」。
而 Specification by example 卻強調的是,你應該透過這一系列的手段,利用 BDD 這樣的手法,摸索出一系列可以實作可以測試的正確軟體需求,從而交付出一個成功的軟體專案。
小結
如果你是抱著裡面有什麼厲害的大絕招,去翻這本書的話。我不敢保證你不會失望。因為這本書不太能算是一本嚴肅的方法論。裡面沒有 code,也不介紹任何工具。同時我也不推薦任何專案新手去翻閱這本書,因為這本書並不是什麼印度蛇藥,你一看完就會變成專案高手。
但是若你進行過不少專案,對於測試驅動開發、行為驅動開發、探索用戶需求有著自己的一番見解、疑問、心得。我相信這本書將會顛覆你的世界觀。

Hi, everyone. I want to introduce the new service I recently built at 2012 Facebook World Hack Taipei : 「Paperclip.io」. It is also the "Best Overall" service in Facebook World Hack Taipei.
What is Paperclip.io?
Paperclip.io tracks and collects webpages you liked via Facebook, and organizes them for you. You can browse or search through the liked pages quickly in Paperclip.io.
idea from …
The idea was from a small thing: I always forget what url I ever liked on Facebook. It was really annoying. So finally I decide to build a service to help me to collect and organize this url links.
Features
- automatic tracking and backup
- organized by various types, provides url info and snapshots.
- can reshare to google plus+, twitter, del.icio.us…etc
- searchable!!
demo video
video creditd by htchien
like us on Facebook:
https://www.facebook.com/paperclip.io
======
各位好。這是我昨天才剛推出的新服務「paperclip.io」。這個服務的主旨是要解決一個困擾:我們每天在 Facebook 上都會「讚」過很多網址。但是,就是因為「讚」過的東西太多了,每次要回去找今天或前幾天讚過什麼東西,都很麻煩。
所以最後我決定寫了一個服務來解這樣的困擾,它可以:
- 每天自動備份你曾經「讚」過什麼
- 按照 og:type 分類排好,而且有縮圖、大綱,
- 還可以讓你容易再度的分享到其他服務(如 Google+, twitter)去。
- 最棒的是可以搜尋!!也就是可以快速搜尋你曾經到底「讚」過什麼鬼了!

看了 demo 影片就知道!
這個服務也讓 我跟夥伴 zhusee 同時奪得了 2012 Facebook World Hack 台北站的首獎 (Best Overall)
歡迎各位試用!
如果使用上有什麼 bug 的話,請在這篇文章底下留言。我會儘快處理…
P.S. 因為機器小台,而且光今天用戶就瞬間爆增幾百個...,所以有可能你剛剛匯入的東西有可能不會那麼快跑出來,這目前不是 bug…還請見諒。